With the advent of Large Language Models like GPT, many NLP tasks can now be performed with ease. Sentiment analysis, summarisation, named entity recognition, all the tasks which required dedicated models and significant compute to train, test, and infer can now easily be performed by a single model.
Question Answering is one of the most sought after NLP tasks since it can provide great value to businesses. Some companies are even replacing their entire customer support team by AI Chatbots 👀
In this article, I will be explaining the working of a project I made that performs question answering videos. The video can be a YouTube video or even a user’s own video. This can help in the tasks of finding minutes of a meeting, important topics discussed in a class recording, key moments from a vlog etc.
However, there are a few limitations with LLMs and Question Answering:
1. The context is very short
Simply put, context refers to the short term memory of the LLM. For ex, the base model of GPT4 has a context of 4000 tokens ≈ 3000 words. This means that it will only be able to reliably perform any task on a piece of text as long as the text and GPT’s answer is within 3000 words. Therefore we cannot use LLMs directly to perform question answering over large piece of documents.
2. Only Text
LLMs by definition are Language Models, so they are unable to perform other ML tasks involving computer vision or audio. However, if a piece of information can be represented as text (eg: colours as RGB values), then LLMs are very powerful in understanding the information and performing tasks over that. So in theory, you can edit an image’s properties using GPT even though no text is involved.
So how do we perform question answering over videos?
This project has 2 key key components:
1. Data Processing
2. Question Answering
I will be explaining both the components in great detail and even though it may seem that QnA is the main part, in order to ensure that the application is scalable and loosely coupled, the data processing step is more complex and involves more design choices than the latter.
Data Processing
The application consists of the following separate services:
1. Gateway: This is service that talks to the user frontend and is responsible for sending the initial data to the correct service. For example, if the user uploads a video, it will reach the Audio-Extraction service but if the user uploads plain text, it will directly reach the Embedding-Generation service.
2. Audio-Extraction: This service is responsible for extracting the audio from the video. This is done by using the ffmpeg executable.
3. Transcription: This service is responsible for transcribing an audio file and creating a document consisting of subtitles with timestamps. This is being done by the Whisper model.
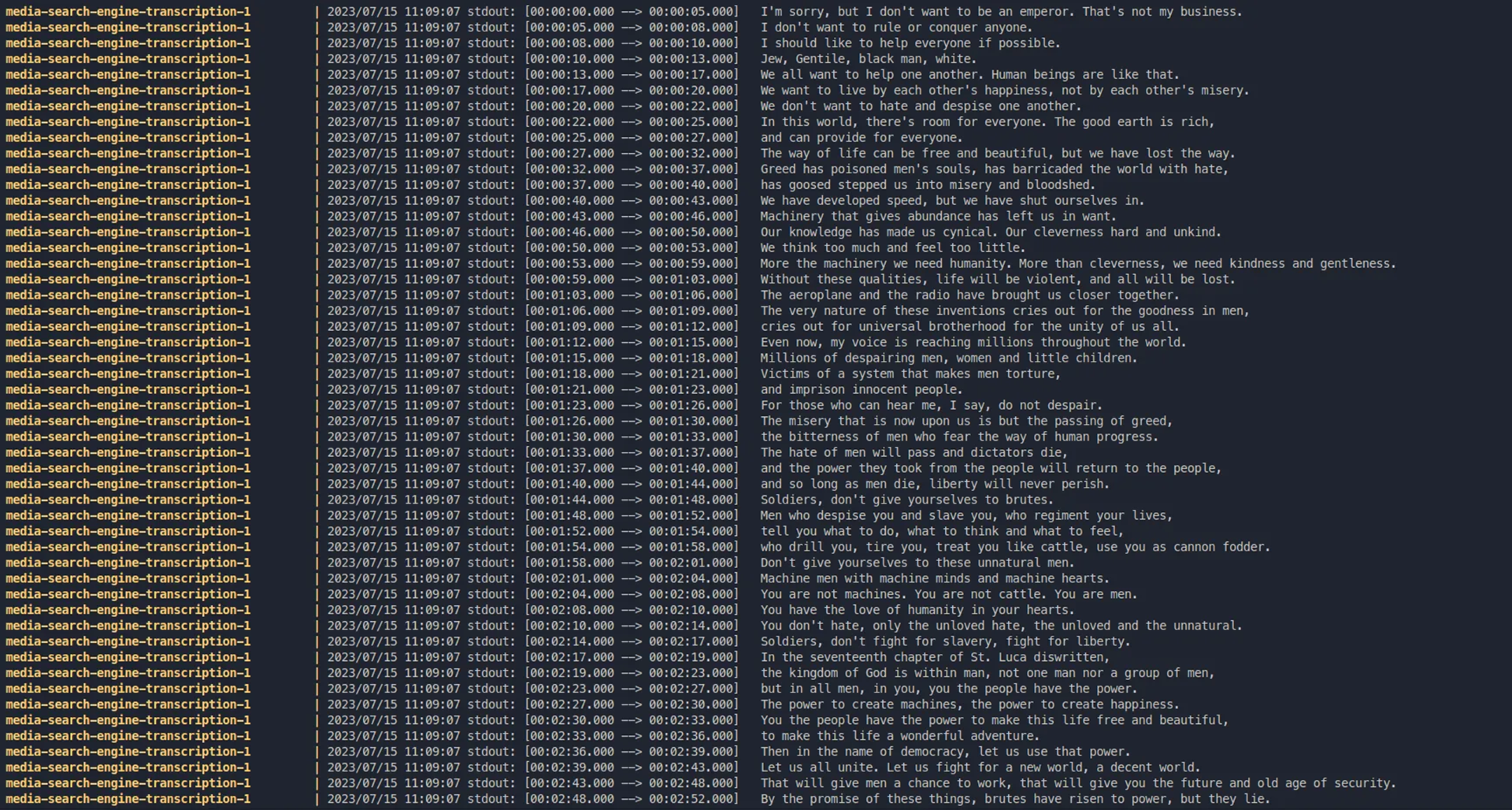
Sample output of Whisper's Speech to Text
4. Embedding-Generation: This service is responsible for generating embeddings over the text dataset. It is also responsible for providing context for a question in the question answering stage. I will explaining embeddings later in the question answering stage.
5. GPT-Service: I am using OpenAI’s GPT3.5 (ChatGPT) model to perform the task of question answering. This service is responsible for building the correct prompt and communicating with GPT to retrieve answer to our questions.
Other Components
Kafka: Apache Kafka is being used as a event bus for the application. It is responsible for inter-service communication and lets a service know that a job is in queue. It has topics (queues) like TRANSCRIPTION_JOB,Kafka: EMBEDDING_JOB etc that corresponding services are consuming from.
Redis: Redis is being used as a cache for the application. When a user uploads a video, a job is created and that job’s status (Pending, failed, completed) is stored in Redis. The frontend continuously polls the server to check if a job is completed or not and updates the Redis value on state change.
AWS S3: Since the application is creating a lot of intermediary resources (audios, transcriptions, videos, embeddings) which are shared between services, we need to have a shared storage. All the resources are uploaded to S3 and are deleted when a job has reached the final stage (embedding generation)
Flow of the application
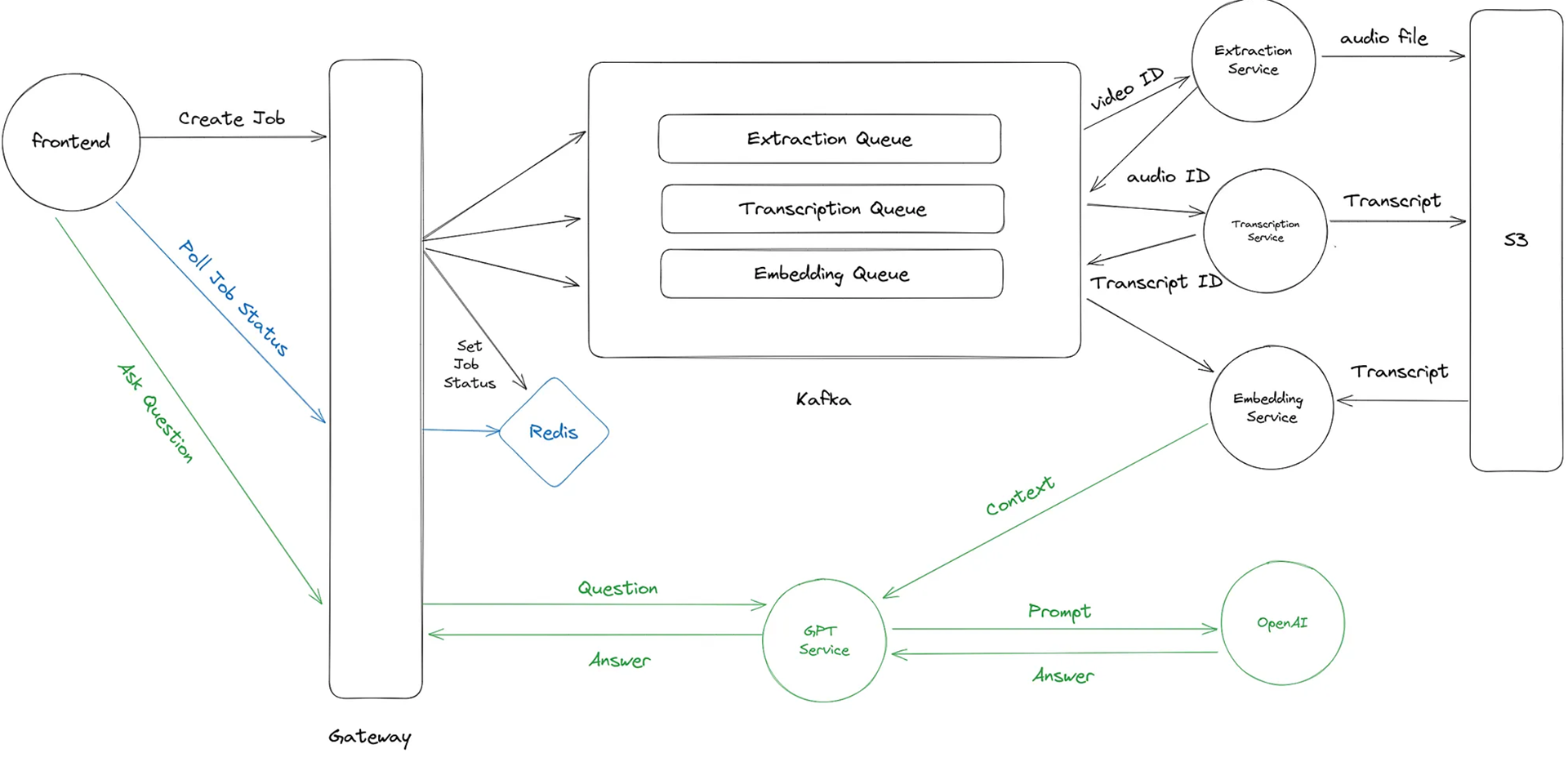
1. User uploads a video or pastes a YouTube link
2. The link/video reaches the gateway where it is tagged with a UUID and is uploaded to the S3 bucket. After upload, the UUID is pushed into a Kafka queue and also returned to the user. It also creates a entry in Redis for the UUID with the status of pending.
3. The user can use another endpoint along with the UUID to constantly poll the server and check if the job is completed or not.
4. The Audio-Extraction service consumes the UUID from the queue and uses it to access the video in the S3 bucket. It then uploads the audio file and pushes the UUID into another queue.
5. The transcription service consumes the UUID, accesses the audio file, creates a transcript, uploads to S3 and pushes the UUID for the embedding service to consume.
6. The embedding service consumes the UUID, accesses the transcript and creates embeddings over it. Once the embeddings for a video are generated, the job is marked completed in Redis and the same information is passed to the user through the polling URL mentioned above.
7. The user can now ask questions over the video using the UUID. I will explain this flow in the next part of this article.
Q. This sounds too complex. Why not do it all together? Why have different services?
Main reason for having different services is independent scaling of them. Maybe the application receives more textual uploads than videos, in which case the embedding-generation service will face more load and can be scaled independent of the other services. Also, the file type of the input can directly be mapped to the corresponding service, skipping the intermediary steps.
Q. Why have S3? Just pass the data around within the application.
The data includes videos which are typically of a large size. Moving it around within the application would mean holding it in memory for a longer time along with chances of data loss while being transported from one service to another. S3 is much more reliable than any storage mechanism I would have come up with myself.
Question Answering
As mentioned above, LLMs have short context and are unable to perform question answering over long form text. So in order to perform our task, we can do 2 things:
1. Text summarisation: We can summarise our long form text to around 3000 words and then ask questions from it since it will be within GPT’s context. But you can imagine, summarising a 40 page transcript to 3000 words would mean a loss of a lot of information.
2. Semantic Search over Embeddings
What are embeddings?
In order for computers to understand the meaning of words, we can assign them numerical representations called text embeddings. These embeddings capture the semantic information of words and phrases. It’s like giving each word a special code that encodes its meaning in a way computers can work with. If you have studied physics/maths, you would know about vectors. Vectors have dimensions that can be used to find spatial and other information about them. Similarly, embeddings are words turned into vectors with multiple dimensions. The embedding model I am using transforms english phrases into vectors of 384 dimensions.
What is semantic search?
Traditional search engines match search queries based on exact keyword matches. However, semantic search goes beyond that by trying to understand the intent and meaning behind the search query. It aims to provide more relevant results by considering the context and semantics of the query, rather than just focusing on exact word matches.
Semantic search algorithms leverage text embeddings to achieve this. By converting words into vectors (embeddings), the algorithms can compare the numerical representations of the search query with those of documents or other text sources. This allows the system to identify similarities in meaning, even if the words themselves are not an exact match. As a result, the search engine can retrieve information that is semantically related to the query, providing more accurate and useful results.
Just how we can perform cosine similarity between two vectors in physics, we can use the same algorithm to find which text vectors are similar and in turn find phrases that are similar in our dataset.
Imagine you’re searching for “healthy recipes for dinner.” With traditional keyword-based search, the system might only look for exact matches of those words, potentially missing relevant content. However, with semantic search and text embeddings, the system can understand that “nutritious dinner recipes” or “cooking healthy meals” convey a similar meaning and provide you with related results.
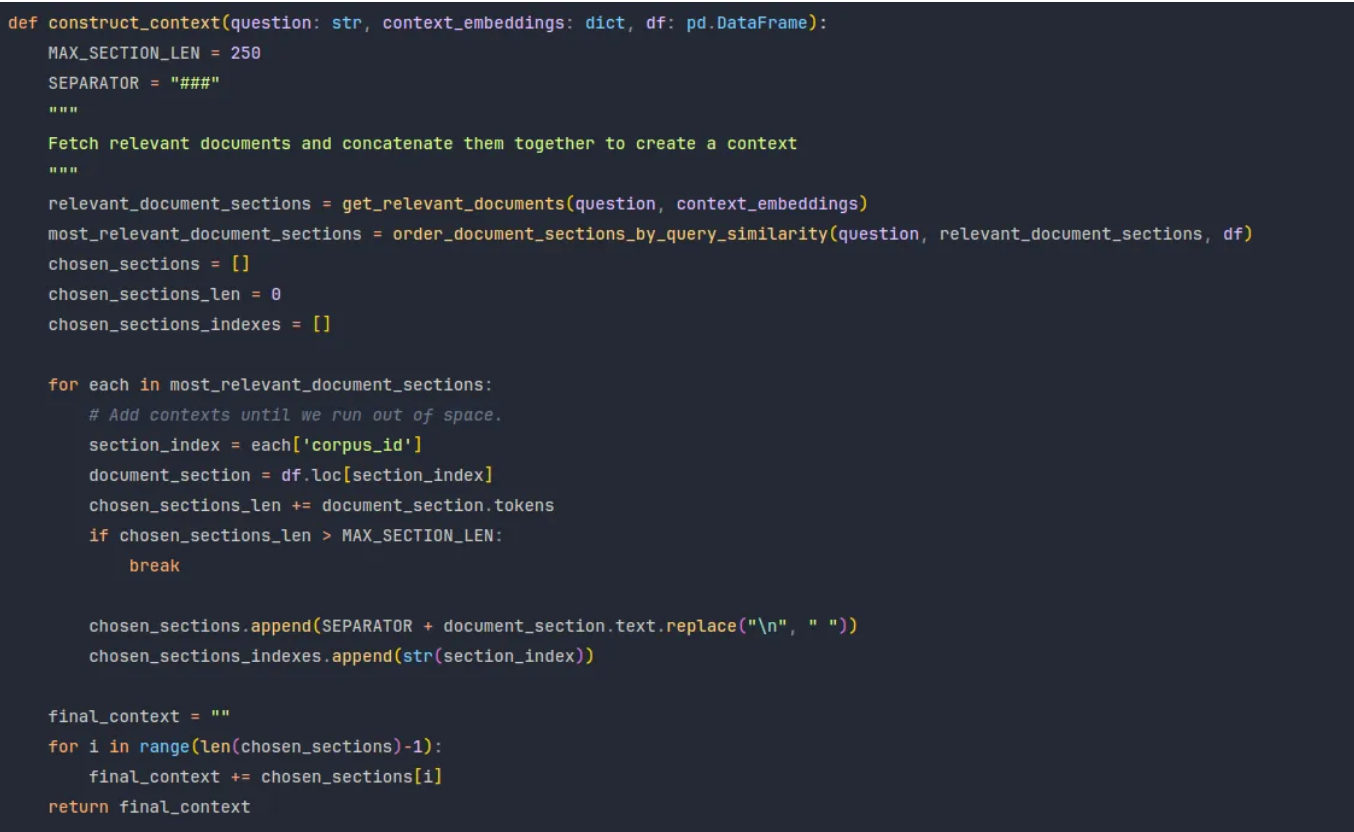
I have also implemented a cross-encoder and a bi-encoder to make the information retrieval task more reliable, however it is beyond the scope of this article to explain them.
Flow of Question Answering
1. After a job is completed and the user is notified of the same, the user can ask questions through a reuest which reaches the gateway.
2. The gateway validates and forwards the request to the GPT-service.
3. Based on the query, GPT-service communicates with the embedding-generation service to retrieve the relevant context for the question. Context here refers to a subset of the original transcript that has the highest probability of containing the answer to our question.
3. The context is appended with the prompt and then passed on to GPT to retrieve a well formed answer in natural language which is then returned to the user.
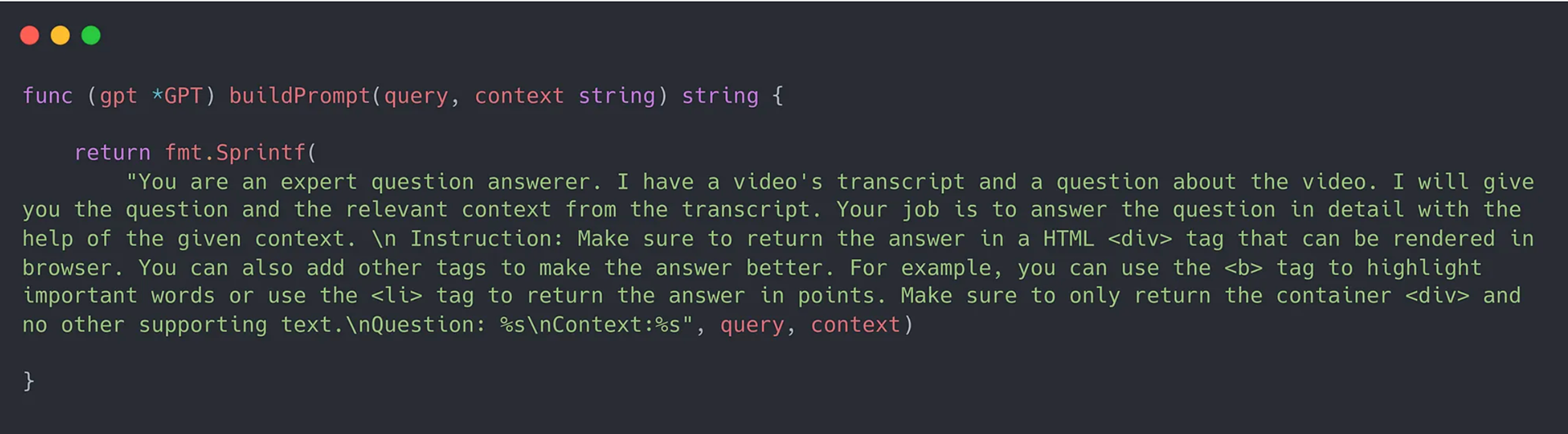
One obvious limitation of this project is that it would not work if the video has no textual dialogue. A way to perform question answering over non textual video would be to perhaps use a model like CLIP to describe the model’s frames and then use that text. However that would require a lot of compute and not feasible as of now.
You can check out the code along with the steps to run here: https://github.com/pi-rate14/media-search-engine
You can check a demo of the application here: https://twitter.com/3__14rate/status/1680162060813082633?s=20



