Modern processors give us the benefits of using threads while writing our software. Threads are essential in distributing workloads and running different functions of the same program parallely. However, there is a common misconception that adding threads is enough to achieve the best performance possible.
In this article, I will be taking the task of counting the total number of primes in the first 300 million natural numbers. I will start by performing this task sequentially using one thread and then we will optimise our code as we move along.
Sequential Computation
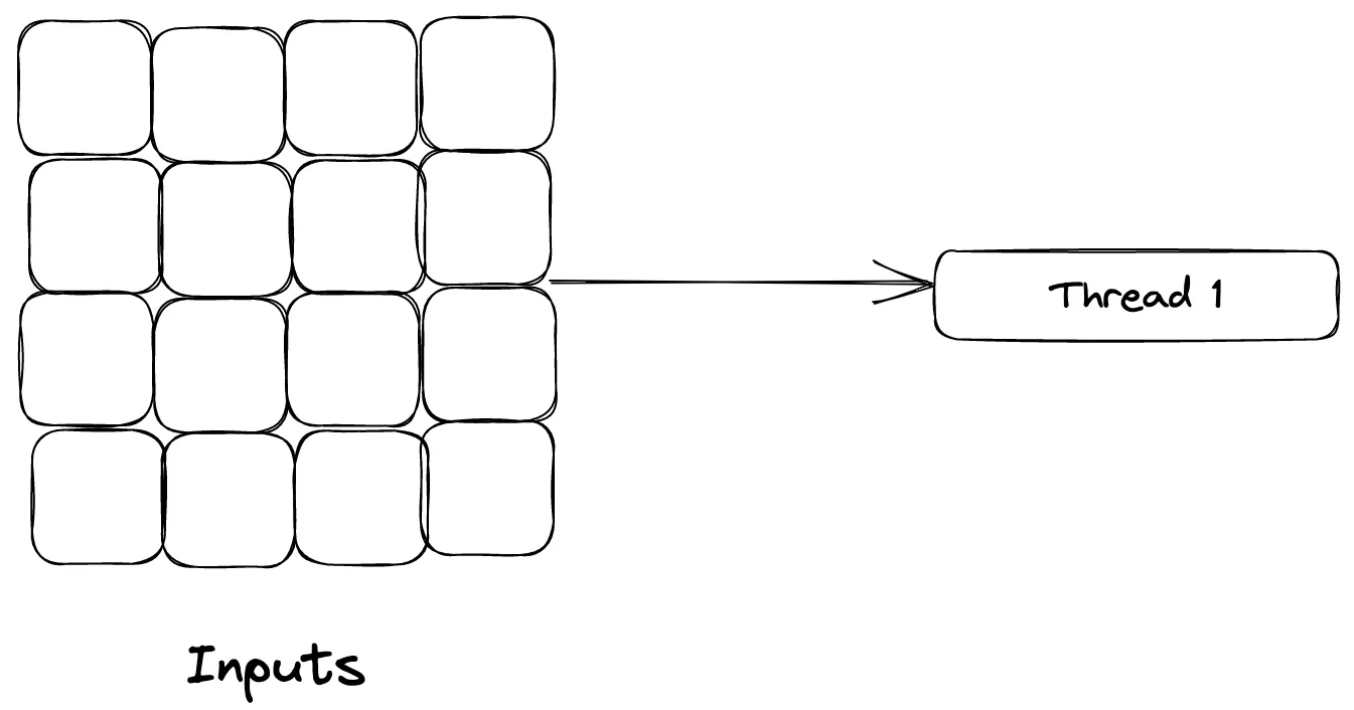

We run a loop from 3 to 300 million, and whenever we encounter a prime number, we increment the value of our global variable TOTAL_PRIMES. It is initialised with a value of 1 to account for the prime number 2. The implementation of the isPrime( ) function is not of concern here.

We found 16252325 prime numbers in 141.614 seconds using 1 thread. Let’s add some more threads and check the performance.
Unfair Parallel Computation
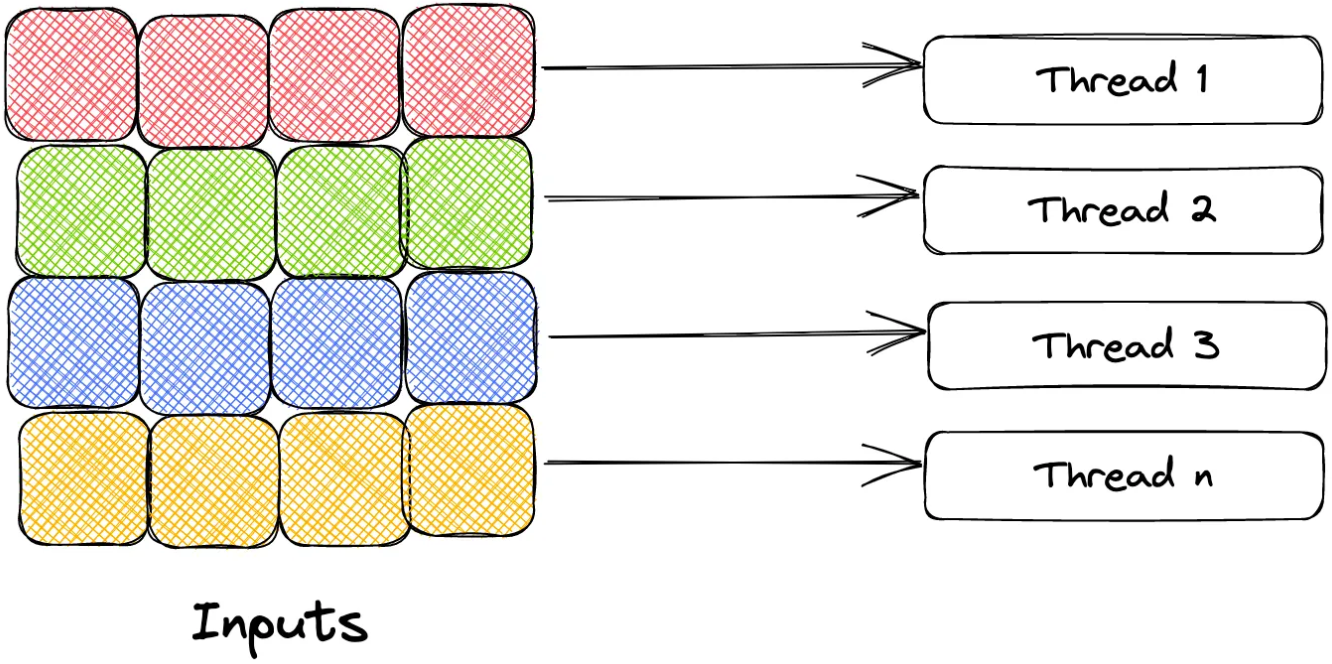

We set a CONCURRENCY_FACTOR of 5, implying that we are going to use 5 threads in our program. We start by dividing 300 million by our CONCURRENCY_FACTOR to create equal batches of size 60 million that can be passed onto each thread to process individually.
In the process function, whenever a thread encounters a prime number in its respective batch, we atomically increment the value of our global TOTAL_PRIMES variable. We need to perform this operation atomically since the global variable can be read and written by all the threads and we need to acquire a lock before we can update its value to avoid bad reads/writes.
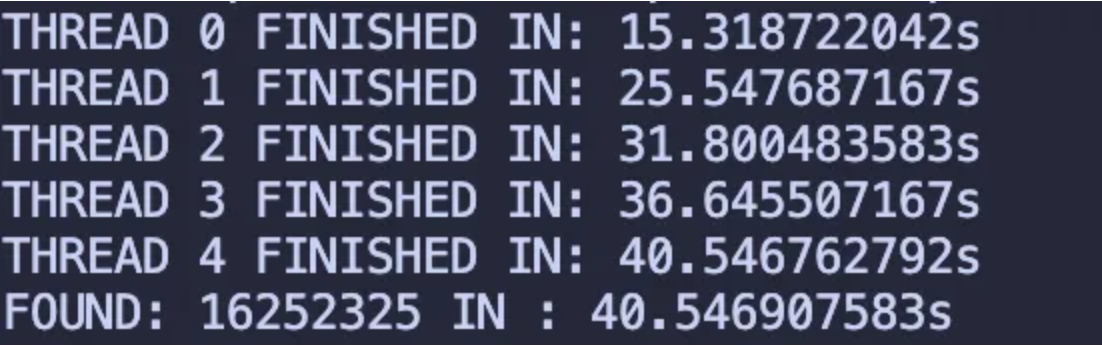
We can see that our program finished in just 40.546 seconds using 5 threads which is an improvement of around 71% compared to the sequential computation. However if you notice the output, you can see that thread 0 finished in 15.3 seconds while thread 4 finished in 40.5 seconds.
Why is this disparity in durations when all the threads are running parallely and the batch size is also same?
It is because of the nature of our computation. We are calculating number of primes in a range. Prime numbers are more dense in the initial batches and get more sparse as the bounds increase. Along with that, the higher batches contain larger numbers, which take more time to be checked for prime-ness by our isPrime( ) function.
Therefore, just adding threads to our problem and distributing workload is not enough. We also need to ensure that the work given to each thread is of similar complexity. We don’t want some of our threads to be more burdened than others for the same task. Hence we call this method unfair.
Let’s try to make this method fair and see if we can improve the performance.
Fair Parallel Computation
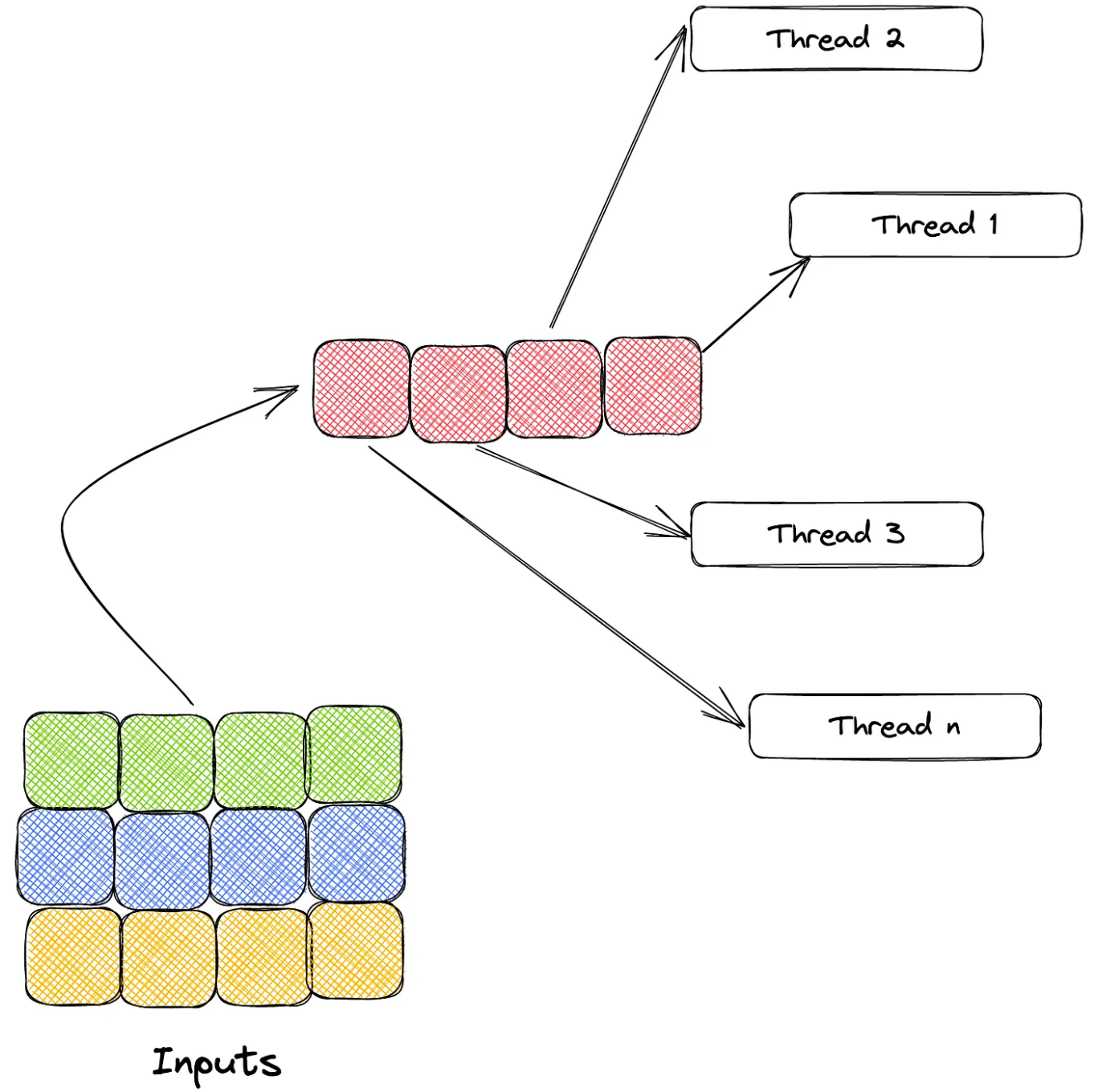

Instead of dividing 300 million numbers in batches, we set a global variable CURRENT_NUM which represents the next number in line which is to be processed. A thread reads the CURRENT_NUM, increments it and checks it for prime-ness, after which it increments the TOTAL_PRIMES variable if the number is prime.
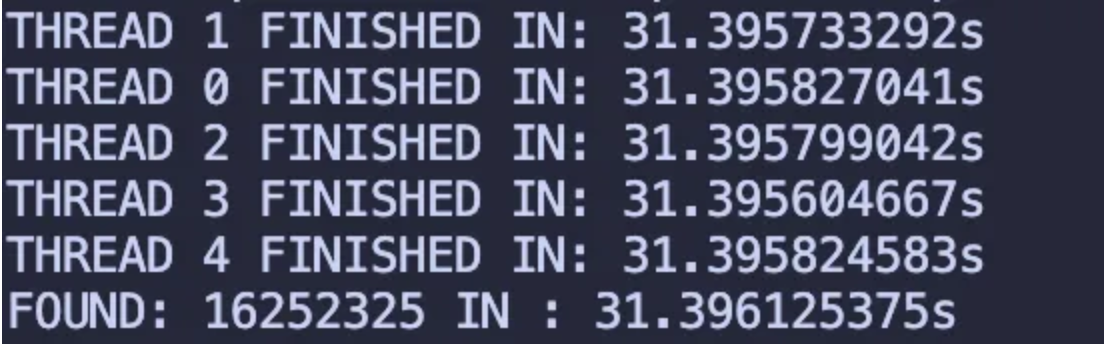
As you can see, each thread has similar workload and all the threads work equally. This leads to them taking same amount of time to finish the entire computation, along with giving us a 23% increase in performance.
Can we optimise this even further?
Fair Parallel with Local Batch

Instead of incrementing the global variable TOTAL_PRIMES every time a thread encounters a prime, we can calculate the total primes encountered by each thread and then add up the values at end to the global variable.
This would save us the overhead of acquiring a lock over the global variable in every iteration where we find a prime.
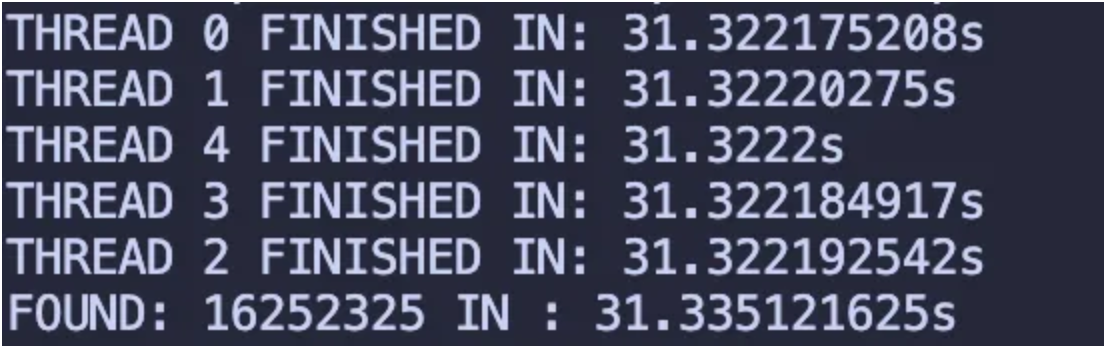
The performance improvement is not significant but it did shave off a few milliseconds. This would scale up with bigger input sizes.
. . .
There can be many more optimisations possible including optimising the processing algorithm, the isPrime( ) function, and also consuming the numbers from a non blocking queue instead of a global variable, eliminating the need of the CURRENT_NUM variable altogether. However the objective of this article was to bring attention to the fact that simply adding threads is not the most optimal choice. A lot of factors go behind designing and implementing a robust multithreaded system.
This article was inspired by Arpit Bhayani on YouTube. Do check him out for in depth explanations of core Software Engineering principles.